The treacherous path to trustworthy Generative AI for Industry

GenAI Chatbots in Industry: From natural language inputs to trusted facts — or probabilistic gibberish?
“In a world of infinite content (data), knowledge (trusted, purposeful data) becomes valuable.”
You can’t avoid the buzz and excitement.
- According to Gartner,“LLMs will become the preferred interface to enterprise data.”
- Just about every SaaS vendor has recently announced (or is about to) their GenAI Copilot.
- Who wouldn’t love simple access to complex industrial data and analytics – finally unlocking the data-powered enterprise?
Read: Will Generative AI Unleash Industry’s iPhone Moment? →
Beyond the hype, however, those working with LLMs for search or analytical query generation are being met with real-world challenges (we don't mean making scripted, cool demos with extremely limited real-world value):
1. Generating working queries from natural language that produce correct results using LLMs is non-trivial.
No, despite the awesome first impact ChatGPT showed and the already significant efficiency gain programming copilots are delivering to developers as users2, making LLMs serve non-developers – the vast majority of the workforce, that is – by having LLMs translate from natural language prompts to API or database queries, expecting readily usable analytics outputs, is not quite so straightforward. Three primary challenges are:
- Inconsistency of prompts to completions (no deterministic reproducibility between LLM inputs and outputs)
- Nearly impossible to audit or explain LLM answers (once trained, LLMs are black boxes)
- Coverage gap on niche domain areas that typically matter most to enterprise users (LLMs are trained on large corpora of internet data, heavily biased towards more generalist topics)
Read More: What does it take to “Talk to our Data?” →
2. LLMs are computationally incredibly expensive and slow compared to database or knowledge graph lookups.
Before the near-future flood of small language models that perform well within their specific focus domains and are an order of magnitude or more cost efficient to run, building production solutions on LLMs will result in a very large cloud bill — which certainly goes a long way to explaining why all hyperscalers are wholeheartedly behind this Generative AI boom!
In addition to potentially crippling costs, LLMs are also very slow compared to low-latency UX expectations in today’s real-time software world.
Example: "What is the largest city in Canada by population?"
| Time to answer | |
|---|---|
| GPT 4 | 1.5s |
| Google Search | 0.5s |
| Knowledge graph/DB lookup | 50ms |
Even very large knowledge graph lookups are many orders of magnitude more efficient — and faster. In an era of sustainability focus, driving up computation with LLMs looks unsustainable.
3. LLMs require context, and using chaining to mitigate context window limitations can result in compound probabilities (= less accuracy).
Without providing LLMs with context, they fail on practically all aside for creative tasks, which their original training corpus (the public internet) supports well. The only means to provide this context is using LLM’s context window, aka in-context learning. When comparing the context windows of popular LLMs to average enterprise data volumes, it very quickly becomes clear that the math doesn't add up. Moreover, context window limitations will persist for years, if not forever.
Cost and latency aside, growing the context window size does not linearly correlate to outcomes. Studies[3] show that the attention mechanism in LLMs works differently for various parts of a long context window. In short, the content in the middle receives less. On the other hand, multiple prompts with shorter context windows allow iteration and optimization of each component individually and even with different LLMs. Moreover, when designed to minimize dependencies among them, it is possible to minimize the effect of compound probabilities and even run them in parallel to reduce latency. Chaining multiple prompts, of course, adds to query volume, hence increasing cost once again.
Read: Why Context Matters for Generative AI in Industry →
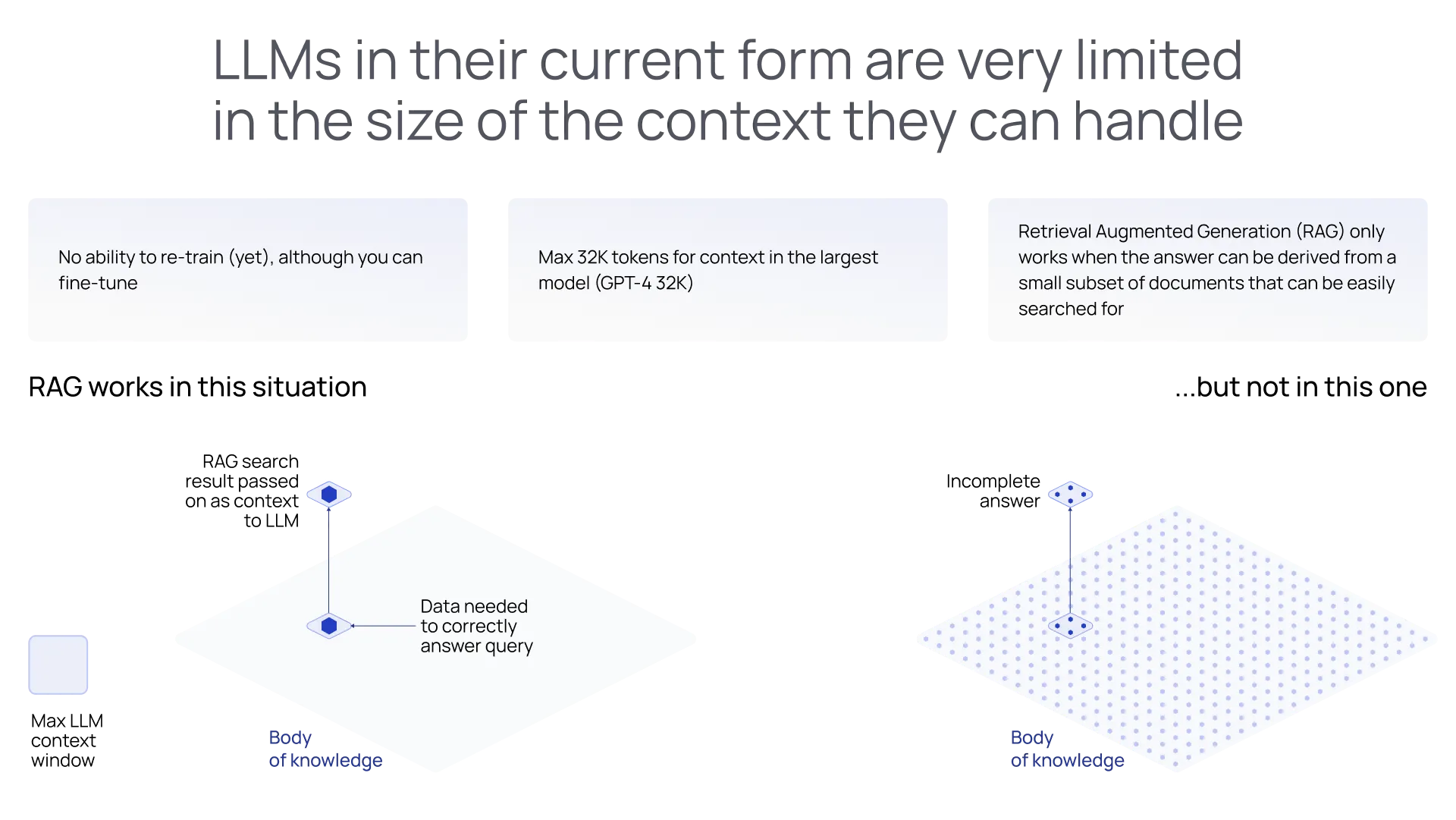
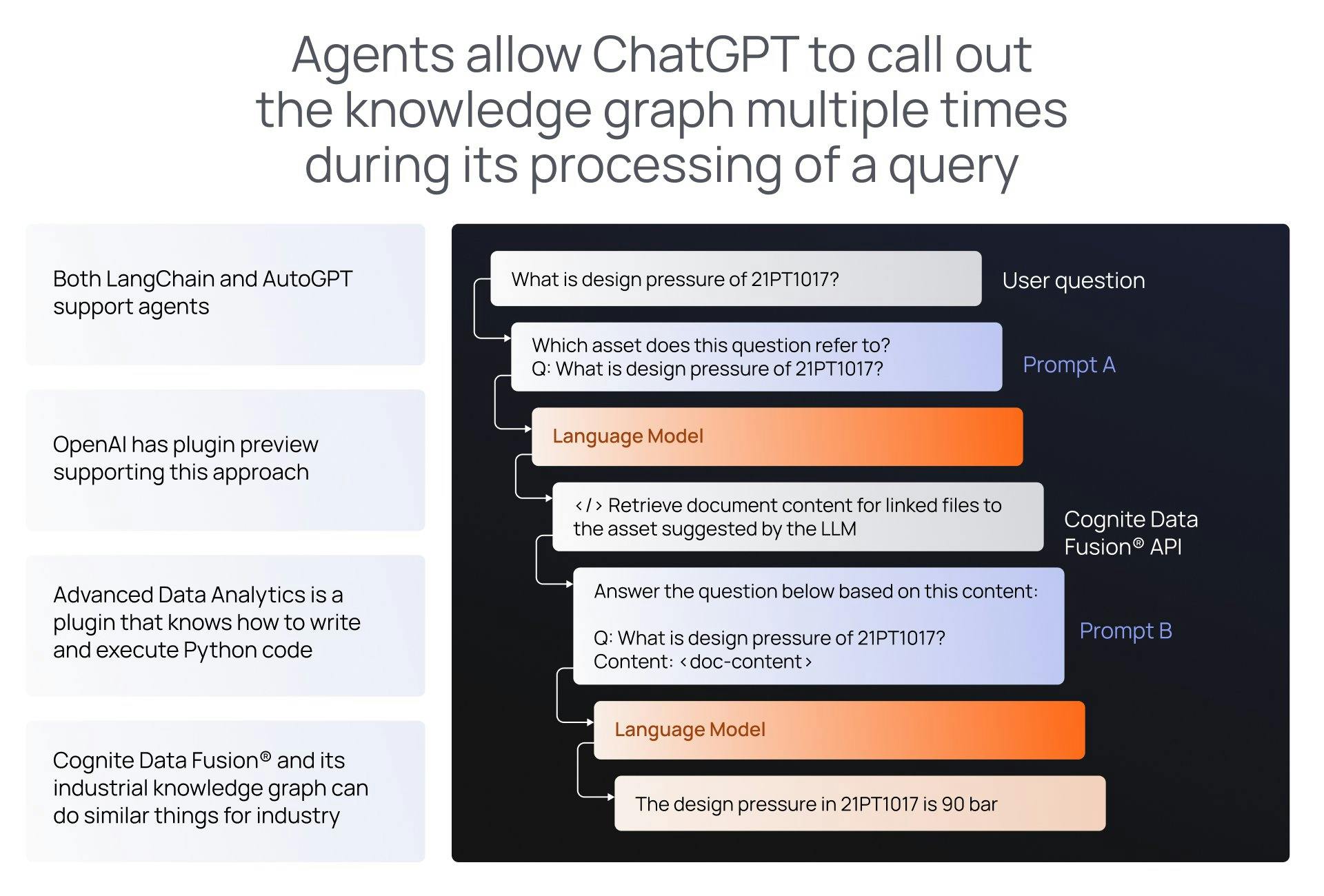
Last but not least, certain types of queries that span lots of facts are not feasible with LLMs alone. For example: “Which assets have a shown heat exchanger fouling after 2021?” In industry domain use cases, the contrast is even more pronounced, as LLMs will typically not have been trained on any proprietary industrial data needed to answer queries, and fitting enough proprietary industrial data into the context window is impossible.
Another impossible task for LLMs is when an answer requires real-time operational data. Ask any LLM if any condenser units in plant A have a temperature below 5 degrees C right now, and they cannot answer. The solution architecture to answering such complex queries is to use agents.
Read: Data Contextualization white paper →
Prompt engineering — including as an interactive model — is the Wild West of possibilities (and security risks!).
Prompt engineering is indeed the new Wild West. But again, more focused instructions tend to work more robustly in practice than longer prompts. We’re again back to chaining (see above).
On security, prompt injections can leak data unless strong data access control is in place. With Cognite AI, all data retrieval is done using users’ assigned credentials, and thus no user will be able to get access to data they shouldn't through prompt injections any more than through conventional interfaces. All existing access control mechanisms in Cognite Data Fusion® apply for generative AI use alike.
When building one’s own LLM agent solution, enterprise data access control enforcement is left to the developer.
4. Understanding that LLM solutions are best assessed on their usefulness rather than mathematical truism. GenAI is not a silver bullet, but a terrific Pathfinder!
You usually do more than one Google search to find the result you are looking for. The same will apply to our future, wherein “LLMs will become the preferred interface to enterprise data” 1.
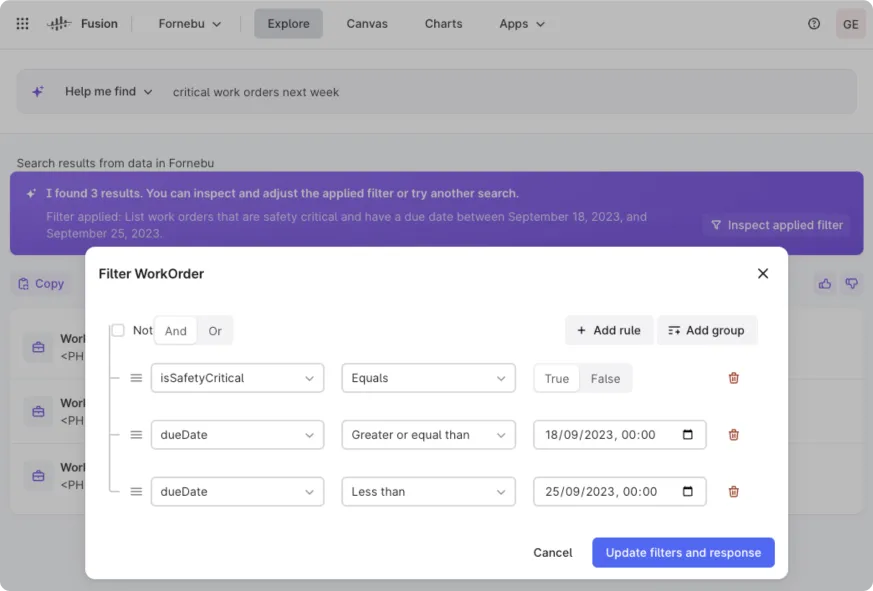
The right design approach is thereby not one that instantly produces the correct result but rather an interactive interface to facilitate the process of finding the right answer, placing the user in control, and using understandable filter inspection (as opposed to only showcasing the generated script to the non-coder user) so that users can review and adjust the suggested filters to find data of interest.
Work around the challenges and limitations by giving users more visibility and control
Once again, the data itself needs to be provided to the LLM-enhanced interface through a deterministic knowledge graph, enabling users to narrow down to relevant parts of the knowledge graph. This interface significantly helps navigate the graph to the right data, even when it might not always directly "zoom" into precisely the node/nodes that initially contain the right answer.
Where is Generative AI for Industry heading next?

Sources:
- Gartner. Quick Answer: Safely Using LLMs With an Active Metadata and Data Fabric Layer. 14 August, 2023
- The economic impact of the AI-powered developer lifecycle and lessons from GitHub Copilot. 27 June, 2023
- Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. Lost in the Middle: How Language Models Use Long Contexts. 31 July, 2023
See Cognite Data Fusion® in action
Get in touch with our product experts to learn more and identify quick wins