What is contextualization?

A simple and clear definition of contextualization to help you understand what it is and why it’s important, so you can share this knowledge with colleagues. Or with an 11th grader…
contextualization (noun)
Contextualization is the process of identifying and representing relationships between data to mirror the relationships that exist between data elements in the physical world. The result is a richer data model that is greater than the sum of its source systems.
The Real-World Context
Several Cogniters started an internal email thread to challenge themselves to explain “contextualization” in simple terms. No mention of “industrial data operations,” “open industrial digital twins,” or “artificial intelligence.” Just a simple description that one of our colleagues could use to explain what contextualization is to their son, an 11th grader in high school.
Our SVP of Product Management, Terje Løken, rose to the challenge and offered a valuable explanation that almost everyone can understand. This explanation is something anyone can use when trying to define contextualization, in plain English, for their colleagues, or establish why it’s the most important aspect of digital industrial transformation.
Terje, could you please scribble the 11th grade explanation of Contextualization per our connect? Thank you.
“Contextualization of data means to uncover and identify relationships between elements of data are connected, but where the relationships are not explicitly represented. This can be done in many ways depending on the type of data and the kind of relationship - some of the techniques are simple pattern matching, others can rely on being able to understand specific data formats, having a lot of domain knowledge, an ability to identify patterns that are not exact matches, etc.”
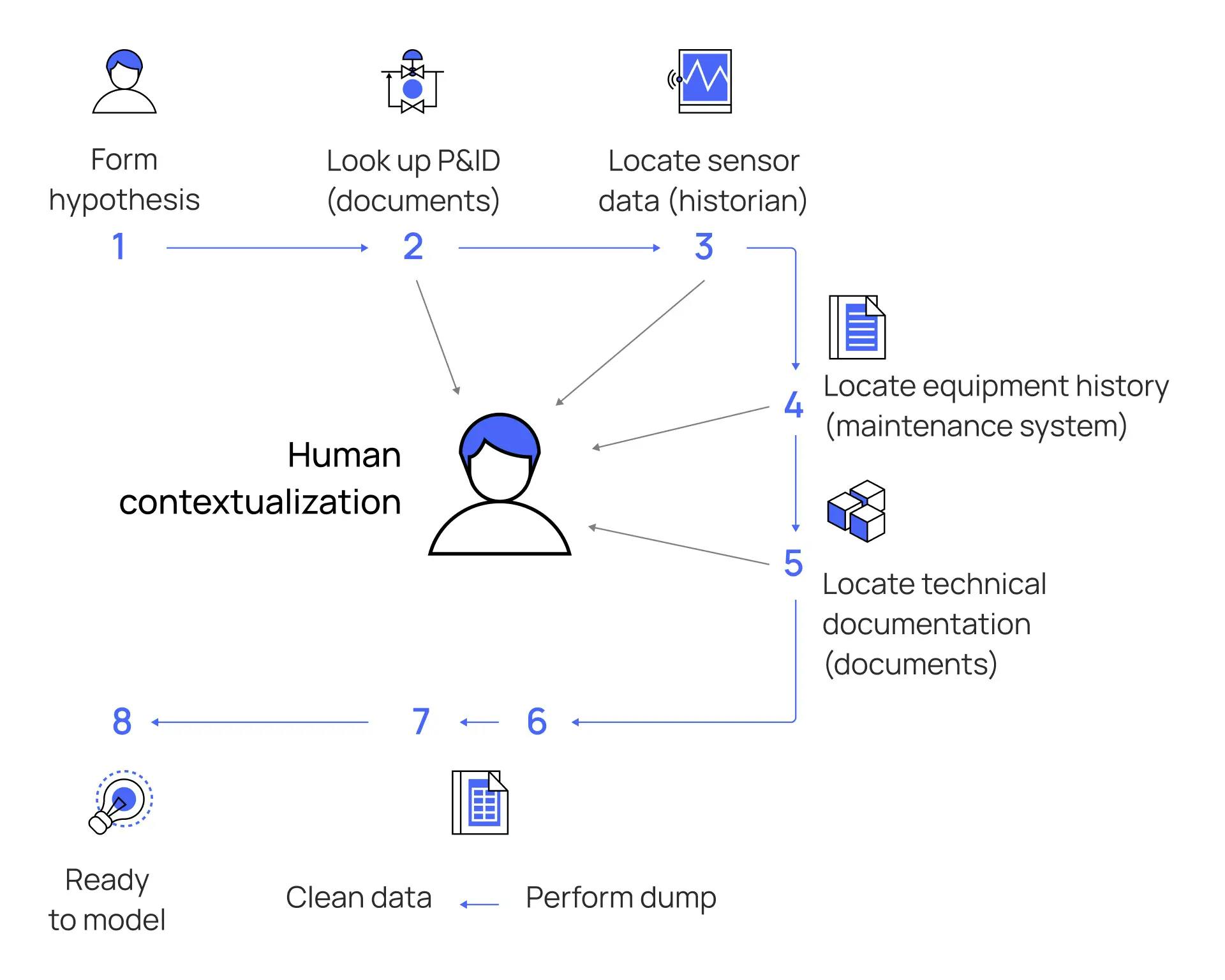
Terje continues and provides an example of “human contextualization”:
“Consider this example of human contextualization: An engineer looks at a gauge and reads off a pressure into a valve. He then finds a P&ID diagram on paper, and using the tag printed on the valve, finds the same valve. He can then trace the pipes connecting the valve to other equipment. Looking in his equipment records he can find the manufacturer of the valve, and then he can locate the paper document with the specification of the valve and its operating parameters. If he wants to inspect the maintenance history of the valve he can look in his maintenance records, but then he has to know that the coding conventions of the tags were slightly changed two years ago, and account for that when retrieving the full maintenance history. Having done all of this, the engineer now has a good picture of the valve's context - its current state, its history, its role in a larger system, and its specification.
This is contextualization of data. If a person does this manually, it takes a lot of time, and the information is probably lost the minute the engineer moves on to the next task.”
We’ve built Cognite Data Fusion® to address these contextualization challenges faced by the majority of industrial organizations:
“Cognite Data Fusion® can do all of this, and a lot more, automatically, or with some initial guidance (training) from a human. Moreover, it can also represent these relationships between the data elements, enabling people to access a rich data model where all of these relationships are present and can be navigated. A contextualized data model is much richer than the isolated data 'islands', and a key to unlocking the value of industrial data.”
See Cognite Data Fusion® in action
Get in touch with our product experts to learn more and identify quick wins